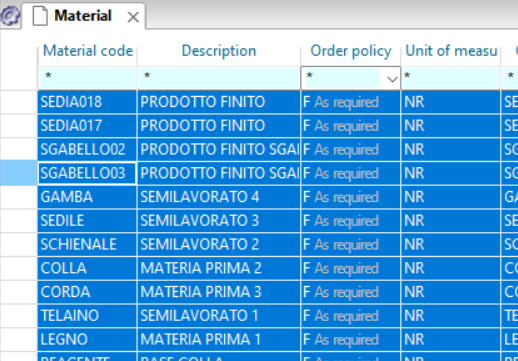
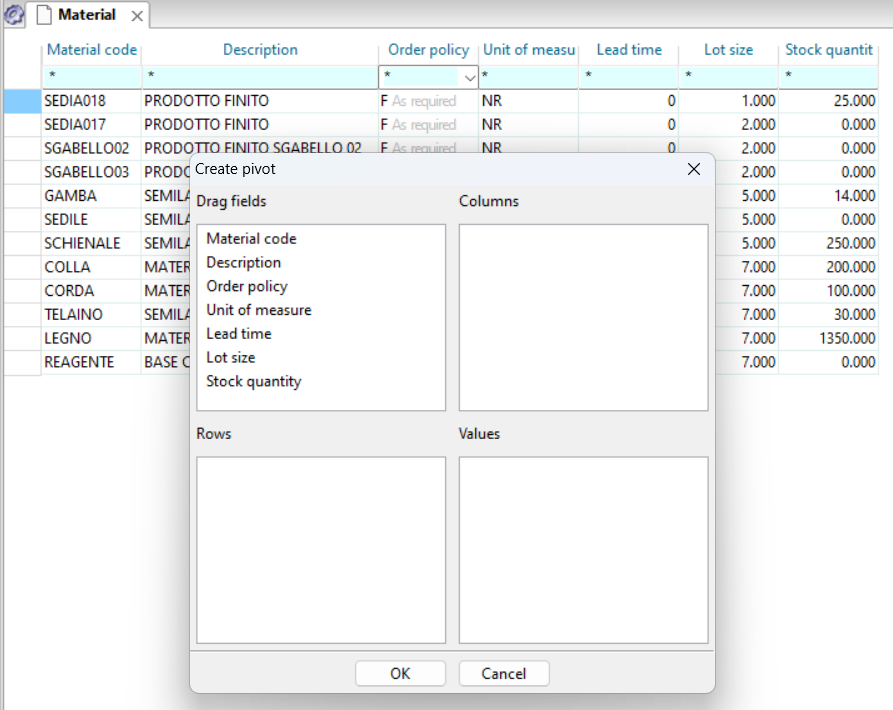
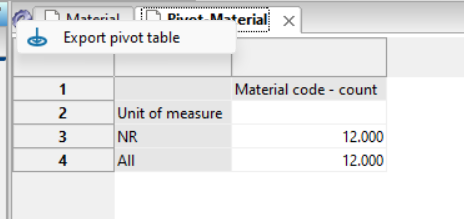
How to import data into Apyesse
Once you have purchased Apyesse and obtained the setup program, the installation steps are simple and guided and do not require system skills or the installation of third-party components. This tutorial uses the demo database that can be optionally installed with Apyesse. This database (Sqlite) simulates the role of the company management system and allows the user to test the Apyesse functionality independently.
Once you launch Apyesse for the first time, the next thing you need to do is create a datastore:
- from the ‘Database’ menu choose ‘New’
- then you select the path and name of the database
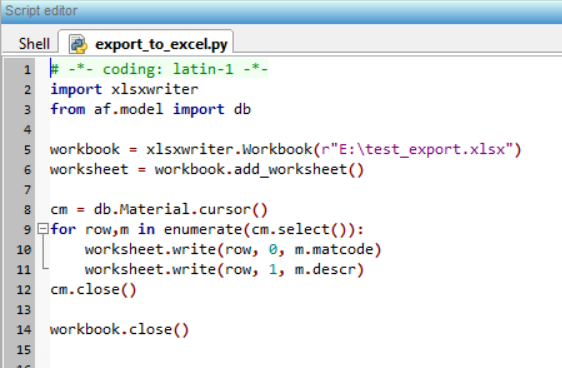
Now we need data to work with. These can be imported from an external source (typically the ERP system) or, in the case of simulations, they can be created from a Python script, the language that Apyesse uses to automate tasks.
As mentioned above, in this tutorial we will use a demo database to simulate the data source consisting of the ERP and we will import data from it via an ODBC connection (for the demo database this connection is already created during the Apyesse installation wizard).
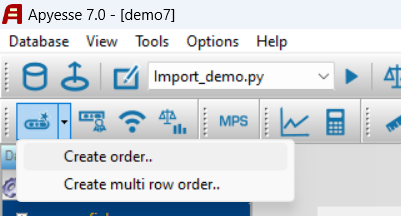
After creating the database, click on the button represented in the following figure for the guided creation of a data loading procedure in Apyesse
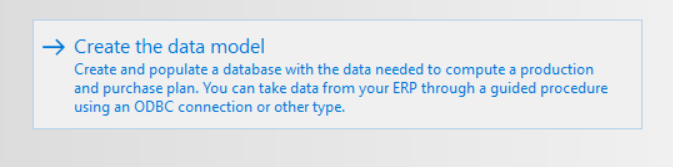
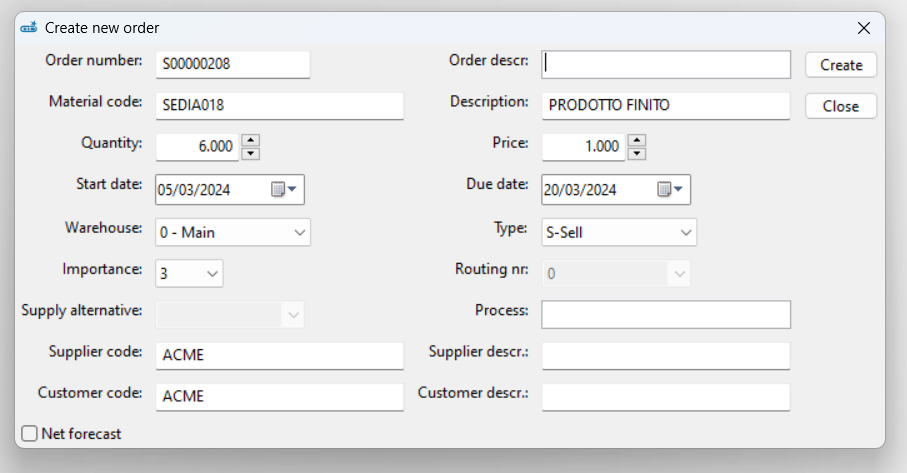
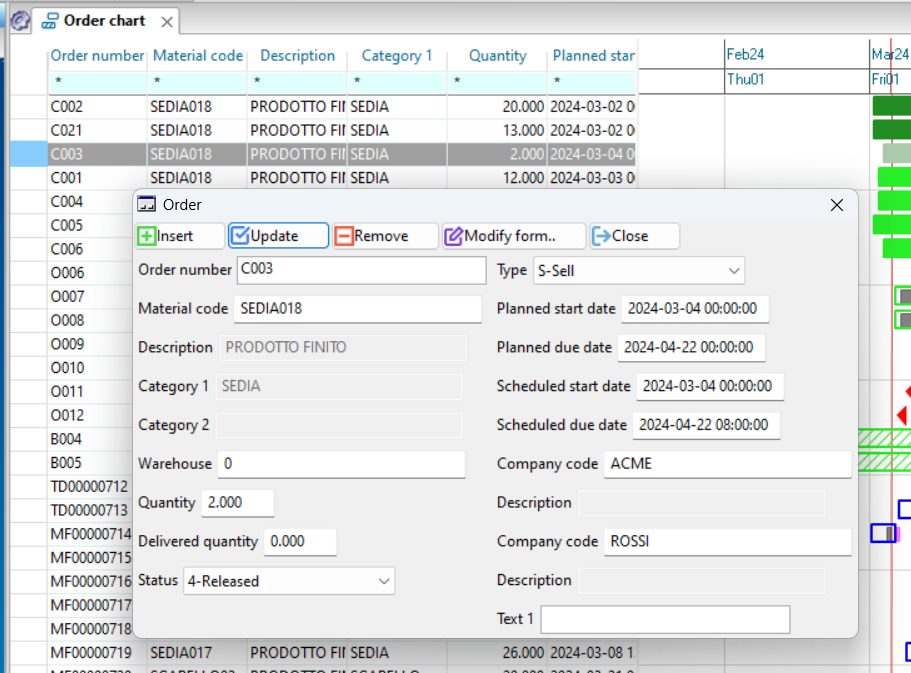
At this point the first page of a wizard opens which facilitates the creation of a procedure to feed the Apyesse database. The first step is the definition of a data exchange project, choosing a new or existing one to modify. Related to the following image:
- if you choose to start a new integration project, you define its name
- and you choose the type of data exchange technology to use
- otherwise, if previous exchange projects have already been created, double click on the corresponding project
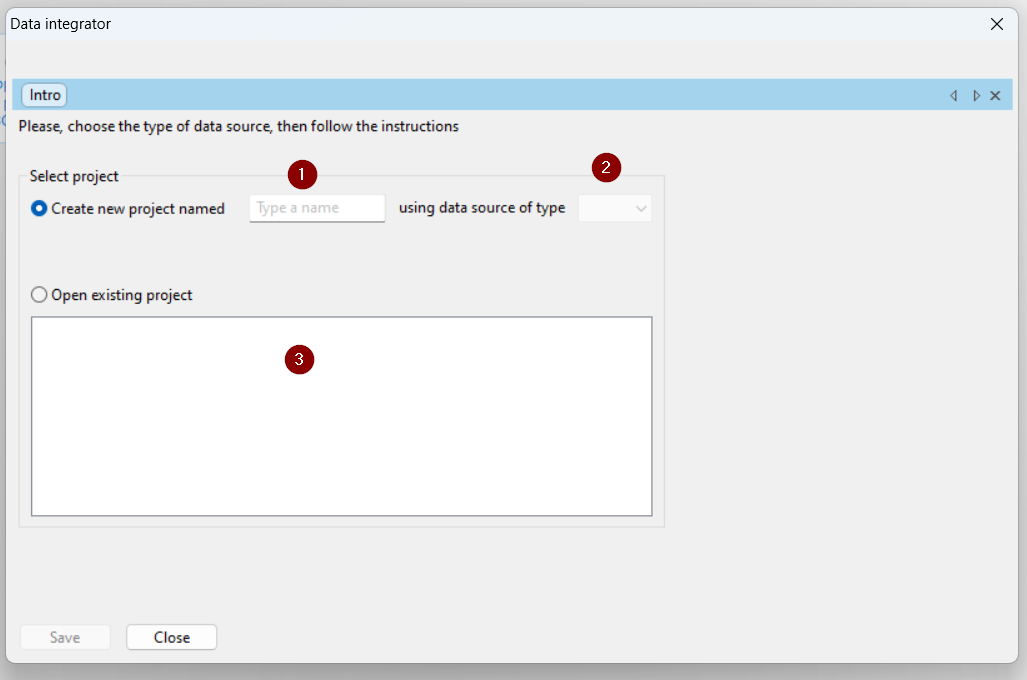
At this point, assuming we continue with the guided procedure for creating a new data exchange project, after selecting the ODBC type, the following dialog box opens, where:
- you select from a list the ODBC connection to use to access the data you want to import into Apyesse. The connection for the demo database is already created during the installation of Apyesse, while for the database of your ERP or other databases it is necessary to set it manually using the methods provided by Windows or by choosing the last item from the list “Create new connection.. “
- indicate the name of the company (real or hypothetical) to be associated with the data model
- then click on ‘+’ to begin mapping the various tables between the data source database and the Apyesse database
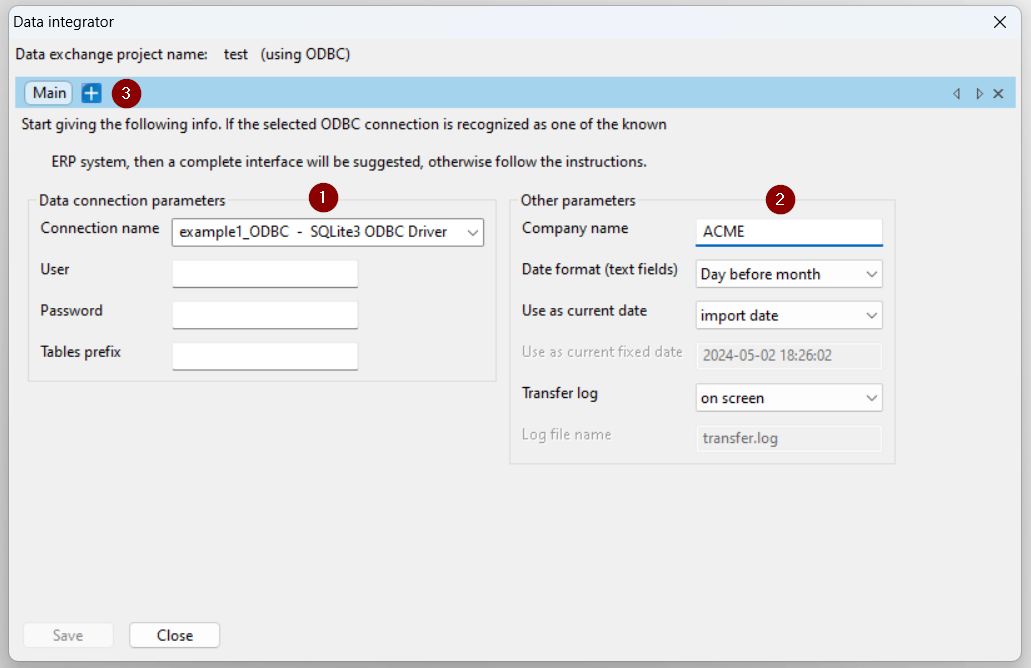
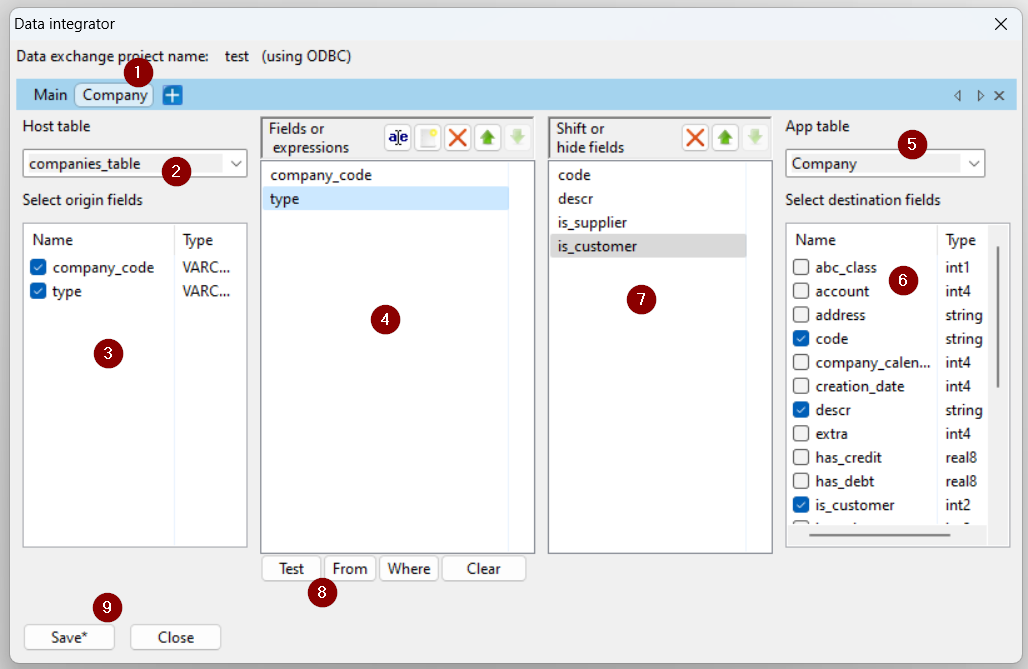
With the first click on the ‘+’ button, using the demo database, the following dialog box opens, structured as follows, with reference to the following image:
- first of all, a page is created for mapping company registry data
- select from the list the name of the data source table (host table) that contains the company data
- once the name of the table has been selected, the list of fields that can be selected from this table is updated
- the fields selected from the list in the previous point appear in this section; it is also possible to insert constants or SQL expressions
- this list contains the names of the Apyesse database tables. Selecting a table updates the page name (1), however it can be modified with a right click on the tab, and the list of table fields is shown (6)
- the list of table fields already opens with the main and mandatory fields selected, to facilitate the user’s operation
- the selected Apyesse table fields are shown in this list and can be moved to those to which they should be mapped in the host table (4)
- these buttons allow you to verify, test and modify the SQL statement that is generated by selecting the table and host fields
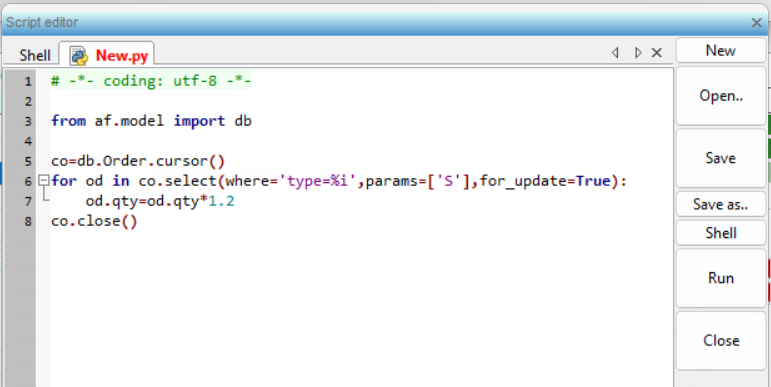
- finally, after having mapped the various tables, click on ‘Save’ to save the data exchange project and to generate the Python script which will then be used to import data into APS
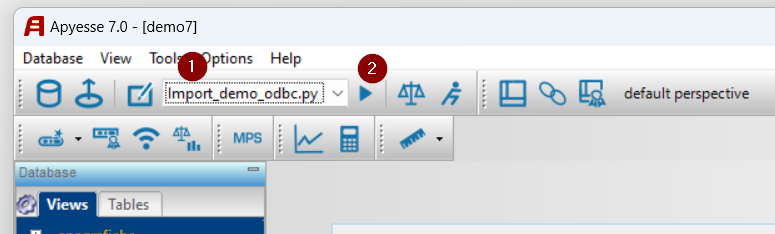
Once you have saved the data exchange project and created the data import Python script:
- you select the script
- its execution is launched
Once the data has been imported into Apyesse, it is possible to launch the calculation engines, consult the plan and make decisions. To do this, you can create custom views and window arrangements to operate in the most effective and efficient way
Configuring the graphical interface
This paragraph describes how to configure the graphic windows to facilitate data consultation and speed up decisions. In particular, a possible arrangement of windows is proposed for the analysis of purchase proposals.
Once the data has been imported, to generate reorder proposals for purchasing and production materials, the MRP must be performed by clicking on the button![]() . After a few seconds, the order proposals will be present in the system.
. After a few seconds, the order proposals will be present in the system.
At this point we want to create an arrangement of windows that allows us to easily identify the purchases to be made immediately and quickly understand the reasons why these purchases are needed.
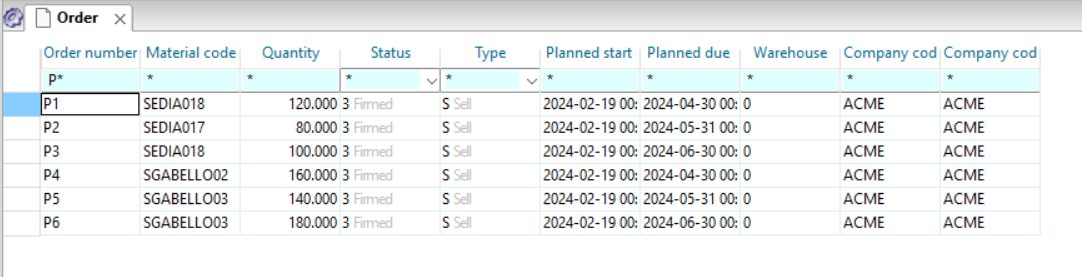
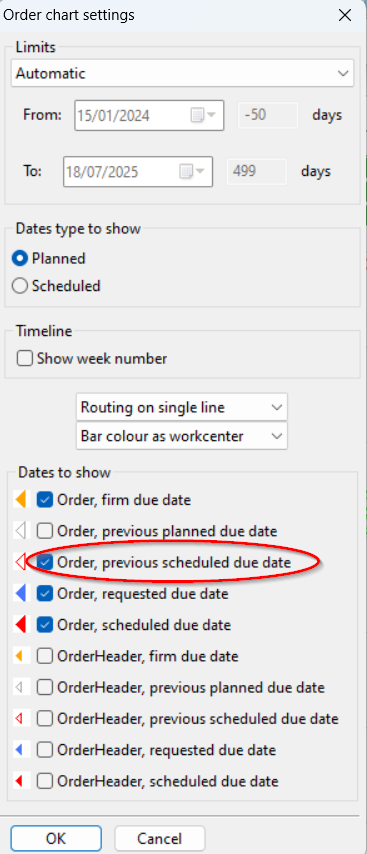
Open the “Order Diagram” window from the following button on the toolbar ![]() and in the window that opens set the filters as shown in the figure:
and in the window that opens set the filters as shown in the figure:

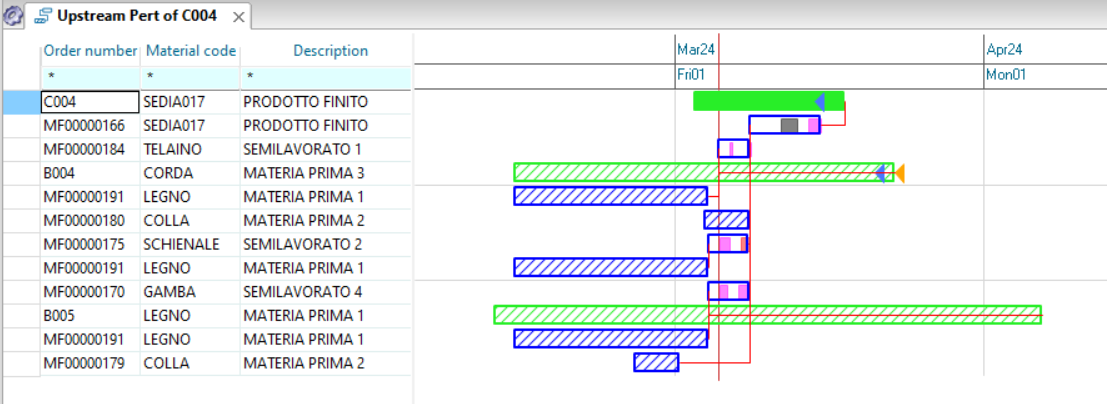
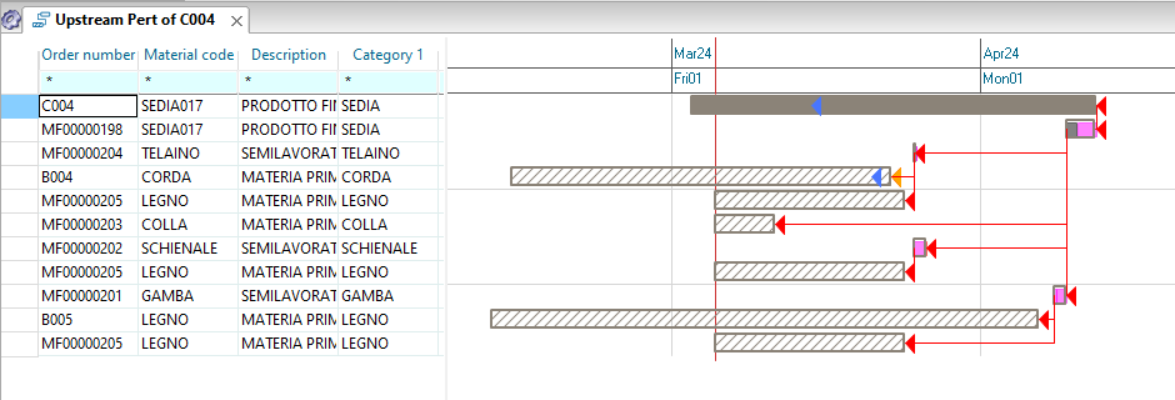
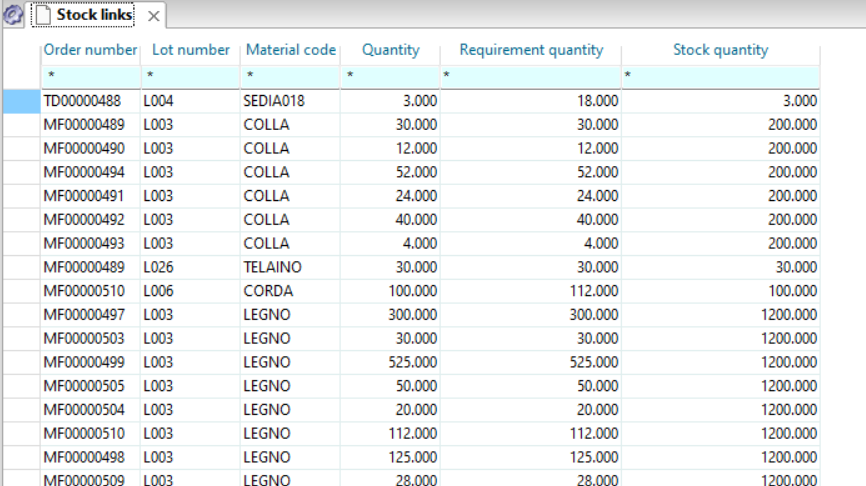
Of all the orders and proposals present in the system we have narrowed our attention to the buy ones (B) with proposal status (0) and with an expected issue date within a week. At this point we want to associate this view with the pegging of the needs to have immediate evidence of the reasons that led the system to make these proposals to us.
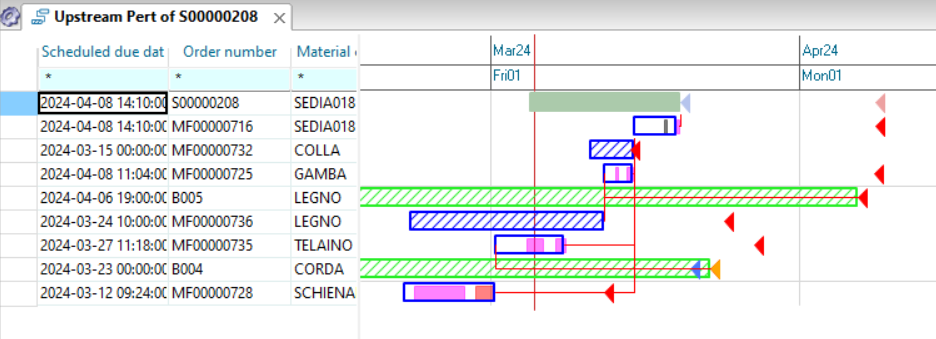
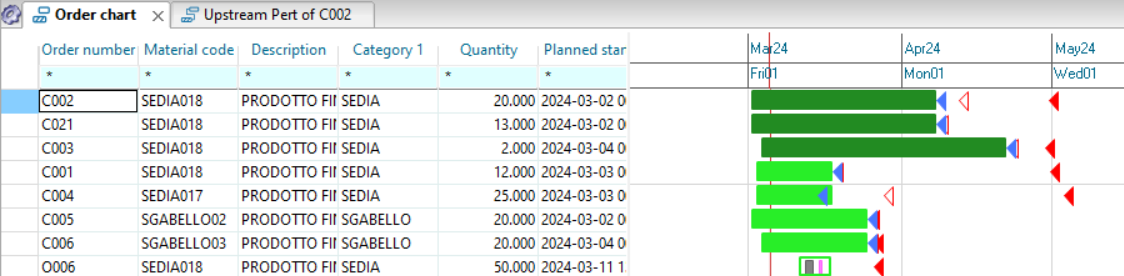
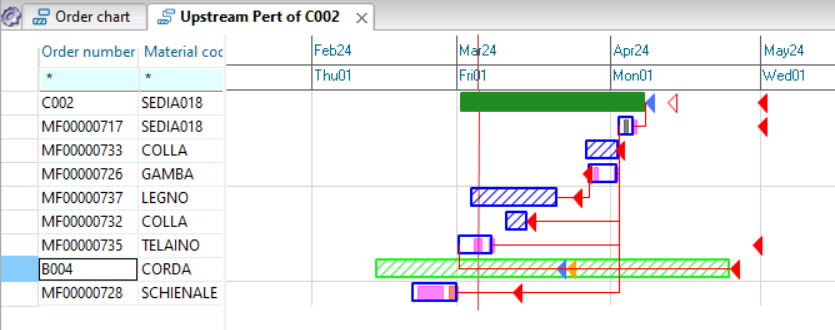
As a first operation we click on the toolbar button ![]() so that the next windows that we open from contextual menus are connected to the initial one. Then by clicking with the right mouse button on the numerator of the proposal you choose “Windows” and then “Downstream Pert view” from the contextual menu.
so that the next windows that we open from contextual menus are connected to the initial one. Then by clicking with the right mouse button on the numerator of the proposal you choose “Windows” and then “Downstream Pert view” from the contextual menu.
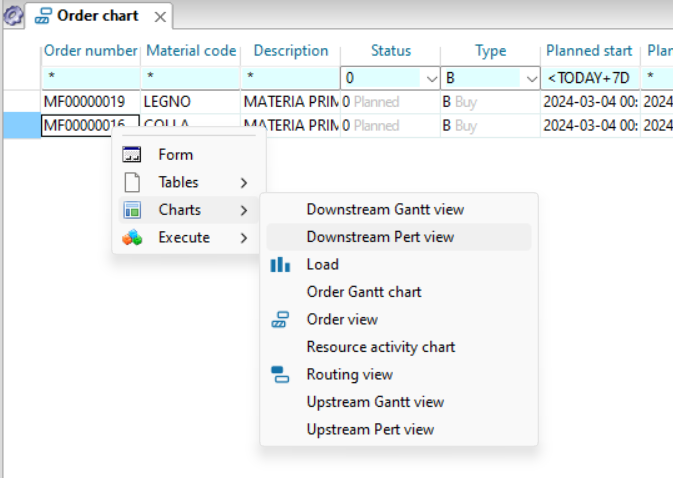
Another window will open next to the original window showing which orders material is required by our proposal. It is important to underline that these two windows are connected to each other: if in the first window you click on a cell of the proposal MF00000019, the second window updates and will show the network of assembly orders of this proposal.

We can now save this arrangement of windows to reuse it in subsequent planning sessions by operating as follows:
- click on the toolbar button

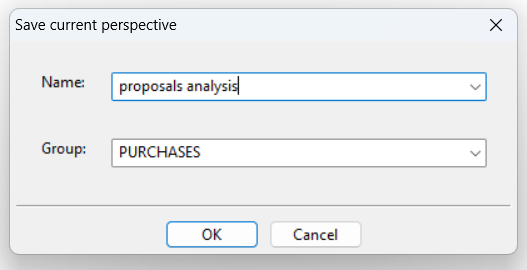
- in the dialog box, enter a name for the arrangement and possibly a group to which it belongs, as in the figure
- after clicking on Ok, the new layout can be recalled from the layout menu as shown in the figure
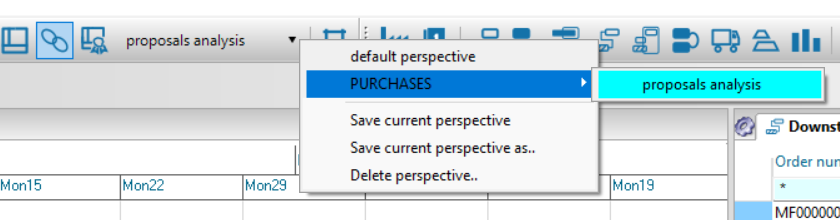
Some notes:
- it is also possible to connect other windows to these and save the additions by clicking on “Save current layout” from the previous menu
- there is no limit to the number of arrangements that can be created
- Changes can be made to the created perspective to analyse, for example, the situation of a single supplier, in order to verify both new proposals and any need for reminders of orders already issued. To do this, simply change the filters in the first view
Please also note that different viewing options are available for each window, accessible via the button ![]() located in the top left corner of the window and which operates on the currently selected window.
located in the top left corner of the window and which operates on the currently selected window.